The metaphor of technical debt is gaining more and more traction. Originally Ward Cunningham used the term for the first time in 1992, describing it like this:
“Shipping first time code is like going into debt. A little debt speeds development so long as it is paid back promptly with a rewrite… The danger occurs when the debt is not repaid. Every minute spent on not-quite-right code counts as interest on that debt. Entire engineering organizations can be brought to a stand-still under the debt load of an unconsolidated implementation, object-oriented or otherwise.”
It is quite interesting to see that many promoters of agile development approaches now consider an ongoing management of technical debt as critical for the development of high-quality and maintainable software. This challenges the idea that development decision should almost exclusively be driven by business value because it is quite hard to assess the value of paying back technical debt or investing time into a solid software architecture. It seems to me that the value of managing technical debt and a solid architectural foundation increases more than linear with project size. If your project is just a couple thousand lines of code and the team is just 2 or 3 people it is relatively easy to add architecture on demand by continuous refactoring. But as soon as we have tens of thousands of code lines, ongoing development of new features and larger teams things become a lot more complicated. In this case the management of technical debt and investments into a solid architectural foundation pay big dividends, as described thoroughly in this research paper.
The problem is how to measure technical debt and focussing on the right kind of technical debt. I will first discuss measuring of technical debt and then delve into the different categories of technical debt and their impact on project outcomes.
Measuring technical debt
To measure technical debt we would need a more precise definition. How do you define “not quite right” in more technical terms? Well, you could define “right” in terms of programming rules, architectural rules and other rules.Then you count the number of rule violations to come up with an estimate for the amount of technical debt in your software system. The technical debt plugin of SonarQube uses exactly this approach to come up with a monetary amount for the technical debt in your system. Unfortunately the devil is in the details. How do you weight different kinds of violations? What is your cost basis? Which rules are checked in the first place? Are those rules really relevant? If you go with the default configuration you will find that a lot of the built-in rules are not really relevant by not having a measurable impact on software quality or maintainability. On the other hand important factors like the conformance of your system to an architectural blueprint, coupling metrics and structural soundness are usually not considered at all. That means that you would look at misleading numbers and spend quite a bit of effort to fix irrelevant problems.
So it is important that you come up with your own set of rules and configure your measurement platform accordingly. The rule of thumb is that less is more. Start with a few meaningful rules and then extend your ruleset over time if you discover that important flaws are not detected by your rules. To decide if a rule makes it into your ruleset always ask yourself how much impact a violation of this particular rule will have on the quality and maintainability of your system and how hard it would be to fix violations later down the road. Obviously we should focus on rules with relatively high impact and/or high repair cost. At the end of this article will introduce an example ruleset, that has worked very well in my own company and for many of our customers.
Categories of technical debt
It makes sense to categorize rules so that it becomes easier to see the big picture and not getting lost in the details of very specific technical rules. Here are some obvious rule categories:
- Local Programming rules, like “no empty catch statements” etc.
- Rules based on automated testing and test coverage
- Rules based on software metrics, i.e. metric thresholds
- Rules based on architecture and dependency structure
Now lets think about the general impact of those categories in terms of repair cost and impact on visible quality and code maintainability. The term “visible (quality) impact” is used to describe things directly detectable by the user of a software system, i.e. bugs und undesired program behavior. The term “maintainability” is used to cover aspects like code comprehensibility and code changeability, i.e. the impact on cost of change.
| Category | Repair Cost | Visible Impact | Maintainability Impact |
| Programming | low | medium | low |
| Testing | potentially high | high | medium |
| Local Metrics | low | low | low |
| Global Metrics | high | low | high |
| Architecture | very high | low | very high |
Programming rule violations are easy to repair because a fix will usually only require changing a single file. Sometimes a programming rule violation will also cause a visible bug so that I classify the impact on visible quality to be medium. The maintainability impact can be neglected because the violation of a local programming rule does not affect overall code maintainability.
When it comes to testing and test coverage the repair cost can be quite high if tests have to be created after development. Ideally automated tests are created together with the code they are supposed to test. The impact on visible quality is also high because missing tests will make visible bugs much more likely. On the other hand missing tests do not have a very big impact on maintainability – except that a good test coverage makes global refactorings a lot easier.
When it comes to metrics we have to make a difference between metrics with a local scope like cyclomatic complexity and global metrics that look at a system as a whole. Rules based on local metrics usually have a low repair cost and low impact on maintenance. If you look at global metrics like ACD (Average Component Dependency, a global coupling metric) the opposite is true. Bad values are hard to fix because global changes are needed and moreover maintainability is very negatively impacted by high coupling. For both classes of metrics you could say that rogue values hardly ever create directly visible problems for the user, so the visibility impact is low.
Our last category addresses architecture and dependency structure. Like for metrics it is easy to see that a bad or missing architecture will not necessarily create visible problems, so the impact on visible quality is quite low. But fixing a broken architecture or adding an architecture after the fact is very difficult and expensive. It is also quite difficult to change a system that does not have a clear architectural structure. All technical debt under this category is also referred to as architectural debt.
Not surprisingly most people who try to track their technical debt focus on the rule categories with high visible impact. But when asked directly which of the four categories have the biggest impact on the lifetime cost of a project most people intuitively agree that this would be “architecture and dependency structure”. Bridging this obvious gap will provide a very good return on investment.
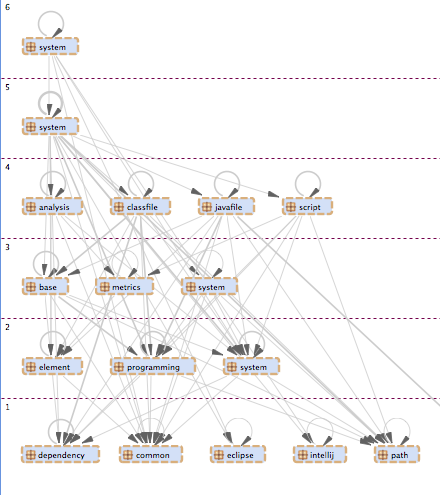
An example for a properly layered dependency structure
The conclusion is that it might not be the best approach to treat all technical debt in the same way. It is important to prioritize rules according to your strategic goals. For a smaller project it makes sense to only focus on the things that affect the visible quality. The larger your project gets and the longer it is supposed to live the more the toxicity of architectural debt will increase. Therefore larger projects should have a strong focus on keeping architectural debt under control.
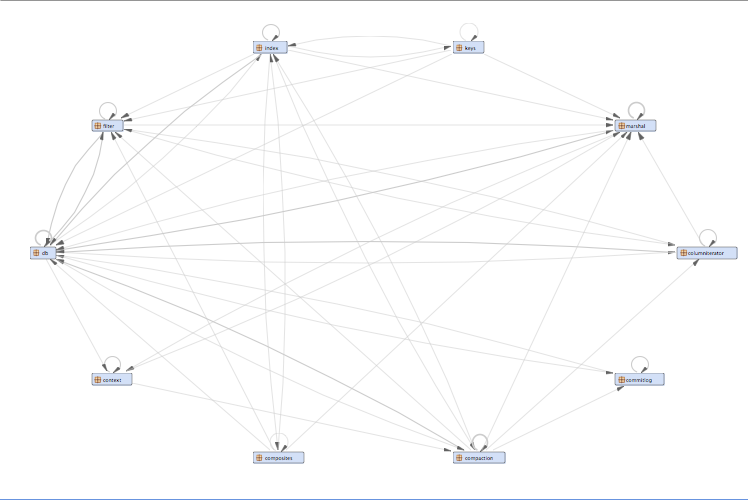
Unstructured dependencies, everything is connected to everything else
Managing Technical Debt
Now that you can actually quantify your technical debt you can make informed decision when to accumulate debt and when to pay it back. It makes perfect sense to accumulate technical debt to meet a critical deadline that is defined by important business constraints. Just make sure that you actually also make a plan to pay down the debt further down the road.
Another advantage of tracking technical debt is that you can have a more meaningful discussion with your stakeholders. If they understand that pushing deadlines too hard will automatically lead to the accumulation of more debt, it will become easier to agree on a balanced approach that always allocates some time for code hygiene and architecture. What I learned over time is that on average you should spend about 20% of your total development effort in this area, potentially more in the early stages of a project and a little less in the later stages. Doing this from the be beginning of a project will lead to quite dramatic cost savings over the lifetime of a project.
Example Ruleset
When designing a ruleset you first want to make sure that all your rules can be checked automatically, ideally in a continuous integration build or at least once per day during the nightly build. Rules that need manual intervention to check them should not be used for technical debt assessment. So you will need to invest in tools and the associated infrastructure. Since some of the needed tools are free and most agile teams already have a build server this should not be a big obstacle, especially when put into context with the potential cost savings.
Your ruleset should also reflect your strategic priorities according to the size of your project. As mentioned above smaller projects require different priorities than larger projects.
The example ruleset is for larger Java projects, but can easily be adapted to other languages. We assume the usage of SonarQube as an umbrella tool to consolidate the results of the different tools used to measure technical debt. Behind each rule we list potential tools to implement that specific rule:
- Define an architectural blueprint and ensure that the code reflects the blueprint (Sonargraph, see also “Designing a DSL to Describe Software Architecture” and “Love your Architecture”)
- Avoid cyclic dependencies between packages (Sonargraph, JDepend, SonarQube)
- Test coverage should be above 50% (SonarQube with Cobertura or Emma)
- Keep the overall coupling low (example metric: Average Component Dependency below 70) (Sonargraph)
- No critical or blocker violations in SonarQube (SonarQube with FindBugs, CheckStyle and PMD)
- Duplicated code lines should not be more than 10% of lines of code (SonarQube, Sonargraph)
- No source file should have more than 700 lines of code (Sonargraph)
- Modified McCabe Cyclomatic Complexity of methods should not be higher than 15 (Sonargraph)
- No package should have more than 50 types in it (Sonargraph)
Rules number 1 and 2 focus on architecture and dependency structure. The metric thresholds in 7, 8 and 9 are soft thresholds, i.e. there can be violated if there is a documented reason for it. For rule 5 it is very important to spend some initial time to configure the active rules for CheckStyle, PMD and Cobertura to avoid checking rules without much practical relevance. Rule 5 can be considered as a meta rule because it summarizes all the little rules of category 1. Depending on your configuration that could be dozens or even hundreds of rules.
The rule set has a good balance between the different rule categories described above. In my company violations of rule 1 and 2 will break the build, other violations will create warnings.
I hope you found this blog post useful. Please let me know what you think by adding a comment below.
I think this is an excellent post. However, while you correctly identify that there are different classes of technical debt and they should be treated differently, I am surprised your refer to projects in reference as to which class to emphasize.
In my experience the reason that technical debt exists is that there continues to be a very mistaken approach to software development that is dependent on the project metaphor. Once we realize that software is a product and not a project (small, large or other) then we will make smart decisions about technical debt.
I am curious about your thoughts on this.
Thank you for your comment, Larry. You have got a good point. Unfortunately in most software development organizations you will not get rewarded for a beautiful architecture, but for quick and visible results. The key is to make technical debt also visible, so that people get a chance to make better decision based on better data. Without tracking technical debt it is hard to argue for the investment into invisible things like architecture and well written code.
Great Article, Thank you Larry for bringing up Total Cost of Ownership and Application Lifecycle Management (aka Product Lifecycle Management) : ) I also liked Alexander’s point about being rewarded for “a beautiful architecture”. Whether you take a craftsman or engineering approach, one of the big challenges for our discipline is that most of our product is virtual. Check out the following links. I am very interested in hearing other opinions on this.
Object Oriented Metrics in Practice, http://www.springer.com/us/book/9783540244295
http://www.moosetechnology.org/
http://agilevisualization.com/
http://www.humane-assessment.com/
The biggest limitation with the concept of technical debt, I think, is a human factors issue. Unlike hardware engineers who have the hard and fast rules of physics as a taskmaster, software is extremely malleable. As such, there is the belief that ‘bugs’ can always be fixed later. I also believe that deep down there is an understanding of the cost. The biggest problem is that handling the situations where technical debt may be incurred requires a strength of personality to handle delicate situations (usually, the business drivers are very powerful and can exert a great deal of pressure). Unfortunately, many people do not have the experience or self-confidence to handle these awkward situations.
Having said this, I like the article because it addresses the question (or starts to, in any case) of how to quantify the concept, which is important when trying to negotiate these delicate situations when they do arise.
I always say that having a software development process with a focus on quality and maintainability is much more a social and political problem than it is a technical problem. Implementing a ruleset in the build and measuring technical debt on a regular base is easy to do. It is a lot harder to create a consensus that enforcing this is a good idea.
Excellent article on Technical Debt. I like how you break things down into Categories that is really a helpful way to explain the different types of Technical Debt. I have always found it hard to convince management of the true impact of Technical Debt and this article gives some solid advice how to look at it.
Tom, thanks so much for your positive feedback. I completely understand what you are talking about. Taking technical and especially architectural debt seriously won’t bear fruits immediately, but over time your harvest will grow exponentially. This is a hard concept to sell in a high pressure environment.
I am curious if you have looked at the commerical sonar plugin for technical debt based on SQALE. http://www.sonarsource.com/products/plugins/governance/sqale/
If you have reviewed this plugin I would really appreciate your commentary around its usefulness.
While it is good that the plugin splits up different categories of debt, I am not sure if and how well it measures architectural debt. As you can read in my article I consider this to be the most toxic form of debt. Moreover I think it is quite problematic to add up all those different categories of debt into one sum. Some debt can be ignored, especially if it is in places that are hardly ever changed. It boils down that everybody who uses the plugin must have a very clear understanding what it measures and what it does not measure. You will also need to spend some time to configure the rules to be checked. Otherwise you will get a lot of debt from rule violations that are not worth the effort to fix them.
Thank you for your response. I agree with your points.