Over time software systems tend to develop several negative symptoms: simple changes require a surprisingly big effort to be implemented, changes cause the system to break in unrelated areas, reuse of code in other systems is simply not feasible, the code is hard to read and understand even for the directly involved programmers. One of the main reasons of facing these symptoms is an unintended increase of the overall system coupling.
Except for very small systems the manual control of the overall coupling is a tedious task – a tool-based approach is needed. Sonargraph-Explorer is such a tool and among other things it helps the developer to assess and control coupling and work against its accidental increase. It is the first product built upon the new Sonargraph Next Generation platform supporting Java, C# and C/C++. It offers different visualizations of dependency structures and a powerful scripting engine based on Groovy which allows extending the built-in analysis capabilities.
The following content introduces the needed definitions and terms related to component coupling (one way to express the overall system coupling). It explains how to use Sonargraph Explorer to visualize the corresponding dependencies and determine components contributing significantly to the overall system coupling with a custom script automatically.
Definition of component
“A component is the smallest unit of physical design” [LSD].
In C/C++ a source file plus its corresponding header declaring the interface represents a component (ideally). In C# and Java a source file represents a component. A component might contain several logical abstractions.
NOTE: This is only one definition of “Component” – there are surely others depending on the context. Seeing a “Component” as a container of a (hopefully) cohesive set of functionality, all further explanations can be applied also to more coarse-grained abstractions like “Module”.
Quantify component coupling
In [LSD] John Lakos introduced 3 simple metrics to quantify component coupling:
- DependsOn: If component C is depending on exactly one other component B it has a DependsOn of 2 – it depends on B and itself. If B depends also on A, C would have a DependsOn of 3. The DependsOn counts the number of direct and indirect outgoing (transitive) dependencies plus one for the corresponding component.
- Cumulative Component Dependency (CCD): The CCD is defined as the sum of all DependsOn values.
- Average Component Dependency (ACD): The ACD is defined as the ratio of the CCD to the number of components N (CCD/N). An ACD of 50 of a system states that on an average every component depends directly or indirectly (transitively) on 49 other components. A higher ACD represents an overall higher coupling in the system.
In addition to these metrics we establish another simple metric called “UsedFrom” to complete the picture.
UsedFrom: It represents the inverse idea of DependsOn and quantifies the impact. If component A is used from B and B is used from C. The UsedFrom for A would be 3 – A UsedFrom itself (analog to DependsOn) plus B and C. The UsedFrom counts the number of direct and indirect incoming (transitive) dependencies plus one for the corresponding component.
Worst case component coupling: Cycle!
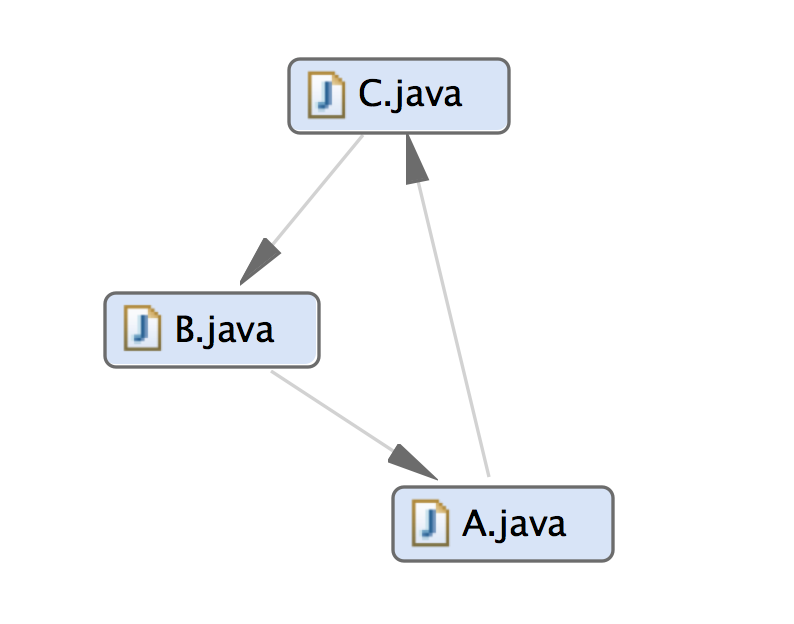
Imagine a simple system consisting of only 3 elements as shown in the figure above. The cyclic dependency structure has the following negative effects:
- Changing one component has impact on all others.
- Testing one component involves all others.
- Reuse is limited to one alternative: Use all!
- Understanding one component requires an understanding of all together.
Cyclic physical dependencies among components inhibit understanding, testing and reuse. [LSD]
The coupling metrics for this system are the following:
- DependsOn: 3 (for all components)
- CCD: 3 + 3 + 3 = 9
- ACD: 9 / 3 = 3
- UsedFrom: 3 (for all components)
Levelizable component structure
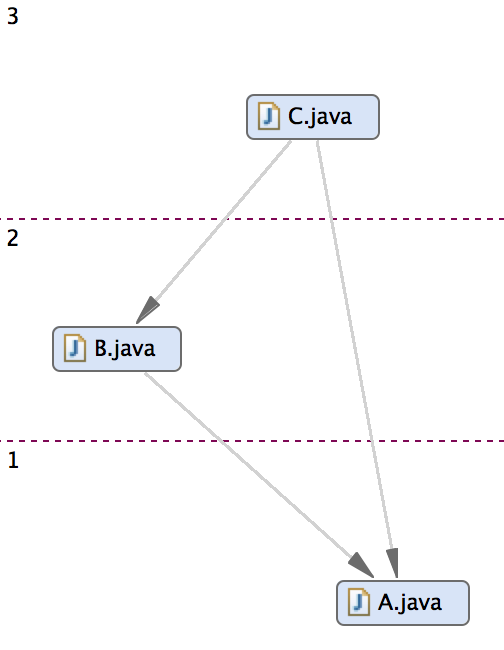
An acyclic dependency structure as shown above has the following positive effects:
- Changing A has impact on B and C as before. Changing B has only impact on C. Changing C has no impact on other components.
- A can be tested in isolation. B only depends on A. C depends on B and A.
- 3 combinations may be reused, A, A and B or all components.
- A clear understanding can be achieved by inspecting first A, than B and then C.
The positive effects can also be seen from the improved coupling metrics for this system:
- Depends On: 1 (A), 2 (B), 3 (C)
- CCD: 1+2+3 = 6
- ACD: 6/3 = 2
- UsedFrom: 3 (A), 2 (B), 1 (C)
Benefit of a levelizable structure: hierarchical incremental testing
Another benefit of establishing an acyclic component dependency graph is the ability to test incrementally on every level. Only the functionality added on each level is tested. Components on level 1 are tested in isolation, since they do not have further dependencies in the system. Testing only on the highest abstraction level makes it very difficult to identify failures in the appropriate components, in order to fix it. It is substantially more effective to test on each level, since the quantity of code is more manageable.
Lowering the overall system coupling has benefits
- Reduced impact of changes – If a component has less direct and indirect incoming dependencies changing that component affects less depending components.
- Testing – If a component depends directly and indirectly on less other components the amount of code that is indirectly tested is less, resulting in a less complex unit test.
- Reuse – If components have less coupling they are easier to reuse in different contexts.
- Understandability – If a component depends directly and indirectly on less other components understanding the overall contract and implementation is easier because it is less complex.
Another term used to express a good degree of decoupling (as opposed to a highly coupled system structure) is “Orthogonality”:
In computing, the term has come to signify a kind of independence or decoupling. Two or more things are orthogonal if changes in one do not affect any of the others. Nonorthogonal systems are inherently more complex to change and control. [TPP]
Inspecting dependencies and base metrics in Sonargraph Explorer
Sonargraph Explorer automatically calculates (among others) the 4 above introduced metrics:
- Used From
- Depends Upon (DependsOn – John Lakos)
- CCD (Cumulative Component Dependency – John Lakos)
- ACD (Average Component Dependency – John Lakos)
In addition to the system scope the 4 metrics are also calculated on module scope. This enables the assessment on module level, too. Sonargraph Explorer allows investigating the coupling easily: After having opened and parsed a system, the Metrics view lists all components with their corresponding metric values. The Used From values are shown by selecting the Element tab, Component level and Used From (System). For further inspection you may select an interesting component and request to jump into the Graph view via the context menu as depicted in the sreenshot below (click to enlarge).

The resulting graph view contains one element FieldAccess. With the different focus modes you can inspect the components a specific component depends upon/is used from or both at a time.
Select FieldAccess and use Focus In/Transitively. This will show all components depending directly and indirectly on FieldAccess as depicted in the screenshot below (click to enlarge).
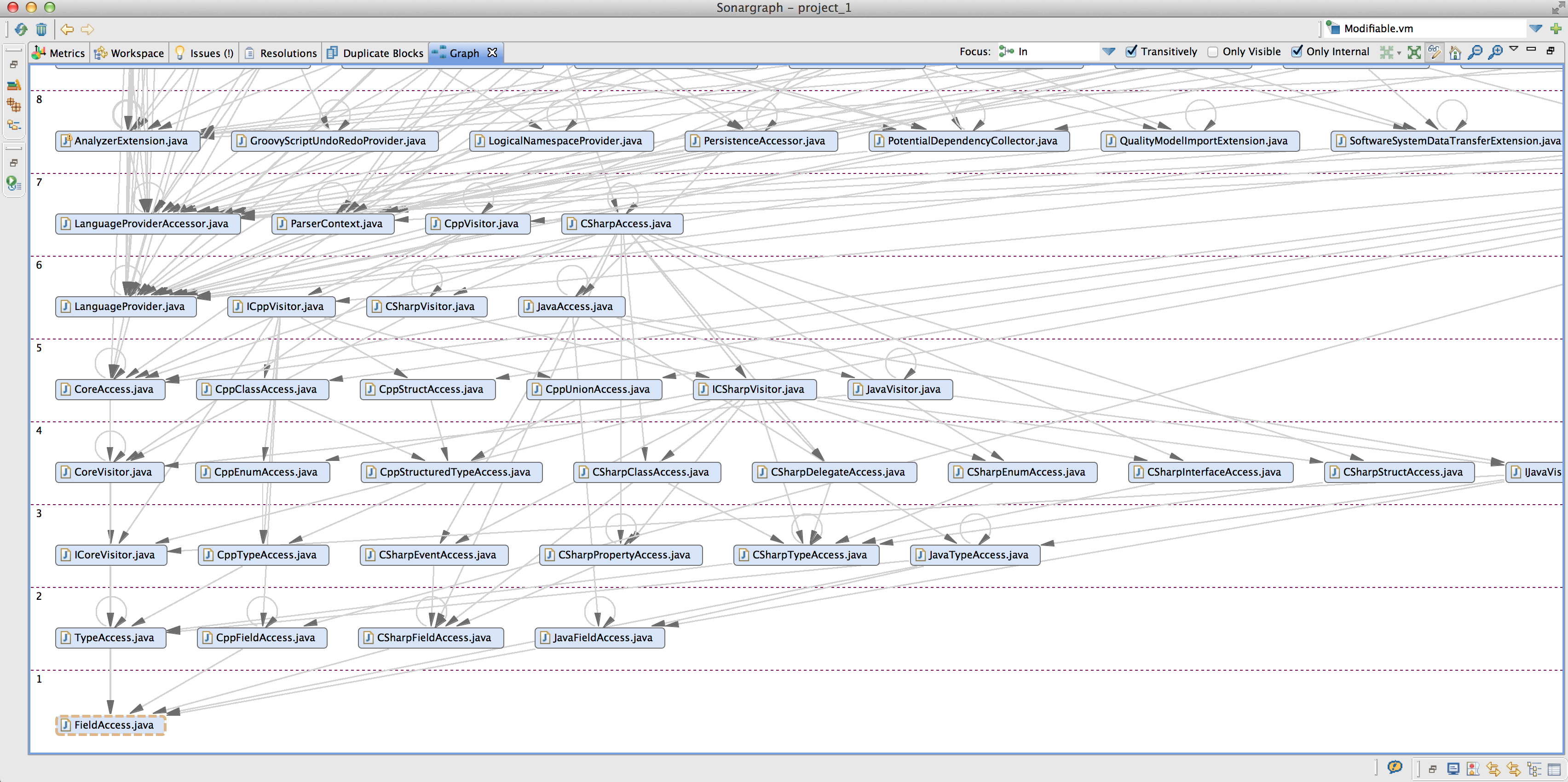
Sonargraph Explorer’s navigation feature allows to go back and forth through already created visualizations. The tool also offers a tree like (exploration view) and a simple table based dependency viewer.
Automatically determining components contributing significantly to the overall system coupling
Sonargraph Explorer offers a scripting engine based on Groovy with access to the underlying parser model which represents the elements and dependencies analyzed in the parsing process and the built-in metrics. Results calculated in a script can be put in different built-in result structures, so that the user can interact with them in the user interface. For example there is a result structure for determined dependencies and the user can jump right to the line of code by double-clicking on the dependency.
The user can choose to write a Core script (i.e. a generic script that it is not language specific – using the Core API) or to write a script using 1 or more language-specific APIs. The advantage of using a Core script is that it may be used for any language, whereas scripts based on a language specific API can only be used for that language. Since components (in our terms) are language specific, we need to create a language specific script.
The script APIs offer a visitor based approach to “visit” the parser-generated model. In general accessing the model looks always similar and consists of the following parts:
- Create a visitor
- Define the action for a specific model element
- Start the visiting process
Our goal is to automatically identify components that contribute significantly to the overall coupling. We want to identify components that have:
- A lot of direct and indirect incoming dependencies (Used From).
- A lot of direct and indirect outgoing dependencies (Depends Upon).
- A high increase of Depends Upon compared to the individual maximum Depends Upon values of the directly used components. If a component has a Depends Upon of 20 and a directly used component has a Depends Upon of 19 then the component itself does not contribute significantly to the increase of the overall coupling.
In this example we use the Java API and explain the development of the complete script in three steps.
Step 1: The following script snippet is already functional and visits all Java source files, collects the Depends Upon values and determines tha maximum Depends Upon value:
//Variables to collect data Map sourceFileToDependsUpon = [:] int maxDependsUpon = 0 //1. Create the visitor IJavaVisitor v = javaAccess.createVisitor() //2. Define the action visiting a specific model element v.onSourceFile { JavaSourceFileAccess nextSourceFile -> Integer dependsUpon = nextSourceFile.getDependsUponSystemMetric() if(dependsUpon != null) //'Depends upon' is only calculated for internals { maxDependsUpon = Math.max(maxDependsUpon, dependsUpon.intValue()) sourceFileToDependsUpon.put(nextSourceFile,dependsUpon) } } //3. Start the visit process javaAccess.visitParserModel(v)
NOTE: It is always a good idea to visit once and collect the stuff you need. After that you can process the collected information without using repetitive visit loops.
Step 2: After having populated the map with (internal) Java source files and their corresponding Depends Upon values, we can iterate over this map and collect/calculate some additional interesting data:
//Variables to collect data Map sourceFileToUsedFrom = [:] Map sourceFileToReferenced = [:] Map sourceFileToDependsUponIncrease = [:] Map relativeImpactToSourceFiles = [:] int maxUsedFrom = 0 int maxRelativeImpact = 0 for(nextEntry in sourceFileToDependsUpon) { JavaSourceFileAccess nextFromSourceFile = nextEntry.key int nextMaxToDependsUpon = 0 List referenced = nextFromSourceFile.getReferencedElementsRecursively(Aggregator.SOURCE_FILE, true, true) referenced.each { JavaSourceFileAccess nextToSourceFile -> Integer nextToDependsUpon = sourceFileToDependsUpon.get(nextToSourceFile) if(nextToDependsUpon != null) { nextMaxToDependsUpon = Math.max(nextMaxToDependsUpon,nextToDependsUpon.intValue()); } } if(nextMaxToDependsUpon > 0) { sourceFileToReferenced.put(nextFromSourceFile, referenced) Integer nextFromDependsUpon = nextEntry.value Integer nextFromUsedFrom = nextFromSourceFile.getUsedFromSystemMetric() assert nextFromUsedFrom != null //If 'Depends upon' was present we expect a 'Used from' value too. sourceFileToUsedFrom.put(nextFromSourceFile, nextFromUsedFrom) maxUsedFrom = Math.max(maxUsedFrom, nextFromUsedFrom.intValue()) float nextFromDependsUponIncrease = 1 - (float)nextMaxToDependsUpon/nextFromDependsUpon sourceFileToDependsUponIncrease.put(nextFromSourceFile, Float.valueOf(nextFromDependsUponIncrease)) //We simply multiply the increase in percent with 'Depends Upon' and 'Used From' //taking into account the in/out coupling float nextFromRelativeImpact = nextFromDependsUponIncrease*nextFromDependsUpon*nextFromUsedFrom; Float nextFromRelativeImpactAsFloat = Float.valueOf(nextFromRelativeImpact) List sourceFiles = relativeImpactToSourceFiles.get(nextFromRelativeImpactAsFloat); if(sourceFiles == null) { sourceFiles = []; relativeImpactToSourceFiles.put(nextFromRelativeImpactAsFloat,sourceFiles); } sourceFiles.add(nextFromSourceFile); maxRelativeImpact = Math.max(maxRelativeImpact, nextFromRelativeImpact) } }
Step 3: After having collected/calculated the corresponding data we need to populate the result structures. We transform the calculated relative impact to a scale of 10 to better visualize the degree of impact on the component coupling:
//We use the tree result structure to directly visualize the scale (omitting 0) result.addNode("Max 'depends upon': "+maxDependsUpon +" - max 'used from': "+maxUsedFrom+" - analyzed "+sourceFileToDependsUpon.size()+" source files") NodeAccess above9 = result.addNode("Relative impact 9 and above'") NodeAccess above8 = result.addNode("Relative impact 8 and above'") NodeAccess above7 = result.addNode("Relative impact 7 and above'") NodeAccess above6 = result.addNode("Relative impact 6 and above'") NodeAccess above5 = result.addNode("Relative impact 5 and above'") NodeAccess above4 = result.addNode("Relative impact 4 and above'") NodeAccess above3 = result.addNode("Relative impact 3 and above'") NodeAccess above2 = result.addNode("Relative impact 2 and above'") NodeAccess above1 = result.addNode("Relative impact 1 and above'") //Sort relativeImpactToSourceFiles = relativeImpactToSourceFiles.sort{a, b -> b.key <=> a.key} for(nextEntry in relativeImpactToSourceFiles) { Float nextRelativeImpact = nextEntry.key float normalizedNextRelativeImpact = (nextRelativeImpact.floatValue()/maxRelativeImpact) * 10 nextEntry.value.each { JavaSourceFileAccess nextSourceFile -> NodeAccess nextImpactNode = null if(normalizedNextRelativeImpact>=9) { nextImpactNode = result.addNode(above9, nextSourceFile); } else if(normalizedNextRelativeImpact>=8) { nextImpactNode = result.addNode(above8, nextSourceFile); } else if(normalizedNextRelativeImpact>=7) { nextImpactNode = result.addNode(above7, nextSourceFile); } else if(normalizedNextRelativeImpact>=6) { nextImpactNode = result.addNode(above6, nextSourceFile); } else if(normalizedNextRelativeImpact>=5) { nextImpactNode = result.addNode(above5, nextSourceFile); } else if(normalizedNextRelativeImpact>=4) { nextImpactNode = result.addNode(above4, nextSourceFile); } else if(normalizedNextRelativeImpact>=3) { nextImpactNode = result.addNode(above3, nextSourceFile); } else if(normalizedNextRelativeImpact>=2) { nextImpactNode = result.addNode(above2, nextSourceFile); } else if(normalizedNextRelativeImpact>=1) { nextImpactNode = result.addNode(above1, nextSourceFile); } if(nextImpactNode != null) { Integer nextOwnDependsUpon = sourceFileToDependsUpon.get(nextSourceFile) Float nextDependsUponIncrease = sourceFileToDependsUponIncrease.get(nextSourceFile) int nextDependsUponIncreaseInPercent = nextDependsUponIncrease*100.0 Integer nextUsedFrom = sourceFileToUsedFrom.get(nextSourceFile) result.addNode(nextImpactNode, "Own 'depends upon': " + nextOwnDependsUpon + " - increase of 'depends upon' over max 'to' 'depends upon': "+nextDependsUponIncreaseInPercent+"% - used from "+ (nextUsedFrom-1) +" source file(s)" ) Map dependsUponToReferenced = [:] List referenced = sourceFileToReferenced.get(nextSourceFile) referenced.each { JavaSourceFileAccess to -> Integer toDependsUpon = sourceFileToDependsUpon.get(to); if(toDependsUpon != null) { List toSourceFiles = dependsUponToReferenced.get(toDependsUpon); if(toSourceFiles == null) { toSourceFiles = []; dependsUponToReferenced.put(toDependsUpon,toSourceFiles); } toSourceFiles.add(to); } } //Sort dependsUponToReferenced = dependsUponToReferenced.sort{a, b -> b.key <=> a.key} for(nextReferencedEntry in dependsUponToReferenced) { NodeAccess nextNode = result.addNode(nextImpactNode, "'to' 'depends upon': "+Integer.toString(nextReferencedEntry.key)) for(toSourceFile in nextReferencedEntry.value) { result.addNode(nextNode, toSourceFile) } } } } }
Executing the script will populate the tree result tab (marked with a ‘!’). When we expand the nodes we can inspect the results. Concrete elements (e.g. a source file) can be selected and opened within its context in a different view (e.g. Source or Graph view) as shown in the following screenshot (click to enlarge):
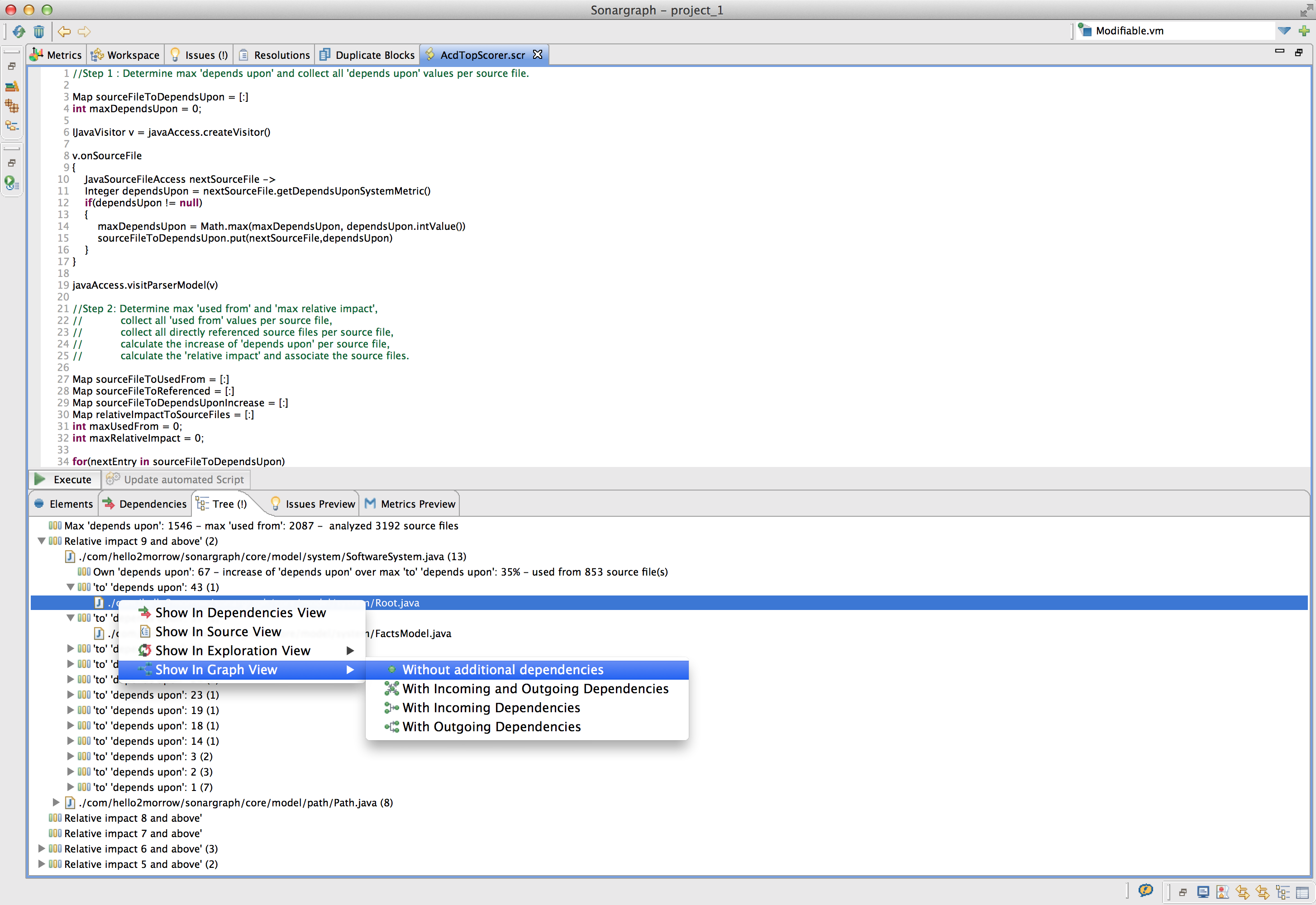
In addition to producing results (like we did in our example) Groovy scripts can create custom metrics and issues (i.e. info/warning/error). Those scripts should be configured as automated scripts, so they are run in the background (automatically) when the parser model changes.
Conclusion
Actively assessing and controlling the overall system coupling requires little time and discipline but has a lot of benefits. With Sonargraph-Explorer it is even possible to extend the built-in analysis and gain interesting new insights. Previously cumbersome manual tasks can be replaced with automated script executions. The full script explained above for all 3 supported languages is part of the product that can be downloaded and tested for free. The tool contains a built-in help system containing also the script API documentation, so it should be relatively easy to get started.
The following two case studies confirm the benefits of using tools like Sonargraph. In one case the defect rate of a mission critical application was reduced by 90%, in another case maintenance cost were lowered by 50%.
References
One thought to “Assess and Control Component Coupling in Software Systems”