In modern object-oriented languages, inheritance is massively used with its pros and cons. Moreover, languages such as Java offer simple inheritance but also allow classes to implement an arbitrary number of interfaces. With inheritance and interface implementation comes one additional ingredient that is naturally expected: method overriding. When a software evolves, you end up with hierarchies involving multiple classes and interfaces with methods definitions and implementations and then, the classes that are part of this hierarchy will be used by some other classes. In this context, it is difficult if not impossible to have control by hand over the usages or overriding classes of methods we would be interested in. Hereafter, I will present this problem in more detail with a very concrete and yet complex enough example, as well as some tools that can empower software architects and developers to gain more control over their code. Read More
Evolving Sonargraph’s Architecture DSL
Sonargraph’s architecture DSL is now about 18 months old and we received a lot of positive feedback from customers bundled with ideas for improving the language. There are now several projects with more than one million LOC that use this language to define and enforce their architectural blueprint. Of course this feedback is most valuable for us and we did our best to implement a good share of the ideas brought to us. This article requires some basic knowledge of our architecture DSL. An introduction can be found here. To use all the features described below you need Sonargraph-Architect version 9.3 or higher.
Expressing Architectural Patterns as Artifact Stereotypes
There are some basic patterns that are used in almost every architectural model. Those patterns describe the relationships between sibling artifacts, i.e. artifacts that have the same parent.
- Layered architecture – here dependencies are allowed to flow top-down within an ordered list of sibling artifacts. If we use strict layering, an artifact can only access ist next sibling artifact. In the case of relaxed layering, artifacts have access to all artifacts defined beneath them.
- Independent – here sibling artifacts are independent from each other, i.e. there should be no dependencies between them.
- Unrestricted – here siblings artifacts have no restrictions in accessing each other. This is not very desirable because it will allow cyclic dependencies between artifacts, but can be really useful when working on a model for a legacy software system.
Use SonarQube + Sonargraph Plugin to Detect Cyclic Dependencies
Cyclic dependencies have long been seen as a major code smell. We like to point to John Lakos as a reference [Lako1996], and a Google search about this topic will bring up valuable resources if you are unfamiliar with the negative effects. In this blog post, I take it as a given that you are interested in detecting cycles and that you agree that they should be avoided. If you see things differently, that’s fine by me – but then this blog post won’t be really interesting for you.
A number of static analysis tools exist that can detect those cycles in your code base automatically. SonarQube was one of them, until the Dependency Structure Matrix (DSM) and cycle detection was dropped with version 5.2. The DZone article by Patroklos Papapetrou (“Working with Dependencies to Eliminate Unwanted Cycles”) and the SonarQube documentation (“Cycles – Dependency Structure Matrix”) illustrate the previous functionality.
I noted that some people are missing those features badly and complain about their removal. The comments of the issue “Drop the Design related services and metrics” and the tweet of Oliver Gierke are two examples.
But thanks to the SonarQube ecosystem of plugins, there is a solution: Use the free Sonargraph Explorer and the Sonargraph Integration Plugin to get the checks for cycles back in SonarQube!
I will demonstrate that the setup and integration of Sonargraph into the build is fast and easy.
How to Organize your Code
In this article I am going to present a realistic example that will show you how to organize your code and how to describe this organization using our architecture DSL (domain specific language) implemented by our static analysis tool Sonargraph-Architect. Let us assume we are building a micro-service that manages customers, products and orders. A high level architecture diagram would look like this:
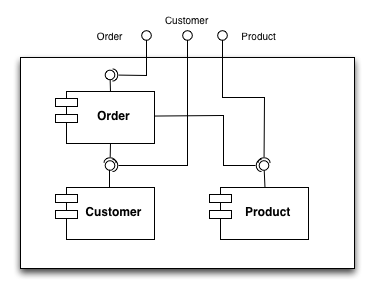
It is always a good idea to cut your system along functionality, and here we can easily see three subsystems. In Java you would map those subsystems to packages, in other languages you might organize your subsystem into separate folders on your file system and use namespaces if they are available.
Automate Cross-Project Analysis
Sonargraph is our tool to quickly assess the quality of a project. I get frequently asked, how Sonargraph supports the Enterprise Architect who needs to answer quality-related questions in the broader context across several projects.
Since we recently released new functionality that allows the automation of re-occurring quality checks, it is now the right time to write a blog post.
Example questions that an enterprise architect wants to answer:
- How frequently does a certain anti-pattern occur?
- How strong is the dependency on deprecated functionality?
- How many of my projects suffer from high coupling?
This article will demonstrate the following core functionality of Sonargraph to answer the above questions for a couple of projects and how to automate this analysis.
- Use a script to detect an anti-pattern (“Supertype uses Subtype”)
- Create a simple reference architecture to detect usage of sun.misc.Unsafe
- Add a threshold for a coupling metric (NCCD)
- Export a quality model
- Use Sonargraph Build Maven integration to execute the analysis.
- Create a small Java project to execute the Sonargraph Maven goal, access the data in the generated XML reports and create a summary.
Meet the Sonargraph Gradle Plugin – and Say Goodbye to JDepend
With the release of Sonargraph 8.8.0 today we also released the first version of our brand new Gradle plugin. It allows you to create reports for any Java project, even those that do not have a Sonargraph system specification. This is a quick and easy way to get some metrics and other findings like circular dependencies about your project. In this article I am going to show you, how you can use our Gradle plugin to make your build fail if your system contains cyclic package dependencies. Believe it or not, there are still people out there that use JDepend for this very reason (I did too, but that was more than a decade ago). Since you can do everything I am describing now with our free Sonargraph-Explorer license including the interactive visualization of cycles, I think you won’t regret saying “Good Bye” to JDepend and “Hello” to Sonargraph. Read More
Designing a DSL to Describe Software Architecture (Part 3)
Connecting Complex Artifacts
After having covered the basics and some advanced concepts in the previous articles this post will examine the different possibilities to define connections between complex artifacts. Let us assume we use the following aspect to describe the inner structure of a business module:
// File layering.arc
exposed artifact UI
{
include "**/ui/**"
connect to Business
}
exposed artifact Business
{
include "**/business/**"
interface default
{
// Only classes in the "iface" package can be used from outside
include "**/iface/*"
}
connect to Persistence
}
artifact Persistence
{
include "**/persistence/**"
}
exposed public artifact Model
{
include "**/model/**"
}This example also shows a special feature of our DSL. You can redefine the default interface if you want to restrict incoming dependencies to a subset of the elements assigned to an artifact. Our layer “Business” is now only accessible over the classes in the “iface” package. Read More
Designing a DSL to Describe Software Architecture (Part 2)
Now that we have covered the basic building blocks in the first part of this article we can progress to more advanced aspects. In this post I will focus on how to factor out reusable parts of an architecture into separate files that can best be described as architectural aspects. We will also cover the restriction of dependencies by dependency types. Read More
Designing a DSL to Describe Software Architecture (Part 1)
Software architecture defines the different parts of a software system and how they relate to each other. Keeping a code base matching its architectural blueprint is crucial for keeping a complex piece of software maintainable over its lifetime. Sure, the architecture will evolve over time, but it is always better to have an architecture and enforce it than giving up on keeping your code organized. (See my recent blog post: Love your Architecture)
The problems start when it comes to describing your architecture in a formal and enforceable way. You could write a nice Wiki article to describe the architecture of your system, or describe it on a Powerpoint slide or with a set of UML diagrams; but that would be quite useless because it is not possible to check in an automated way whether or not your architecture is respected by the code. And everybody who ever worked on a non-trivial project with more than 2 developers knows that rules will be broken. That leads to an ever increasing accumulation of architectural debt with all kinds of undesirable side effects for the long term sustainability of a piece of software. You could also use Sonargraph 7 or similar tools to create a graphical representation of your architectural blueprint. That is already a lot better because you can actually enforce the rules in your automated builds or even directly in the IDE. But it also means that everybody who wants to understand the architecture will need the tool to see it. You also will not be able to modify the architecture without having access to the tool.
Wouldn’t it be nice if you could describe your architecture as code, if you had a DSL (domain specific language) that can be used by software architects to describe the architecture of a system and that is expressive and readable enough so that every developer is able to understand it? Well, it took us a while to come up with that idea, but now I believe that this is the missing puzzle piece to significantly boost the adoption of formalized and enforceable software architecture rules. The long term benefits of using them are just to good to be ignored.
Love your Architecture
The single best thing you can do for the long term health, quality and maintainability of a non-trivial software system is to carefully manage and control the dependencies between its different elements and components by defining and enforcing an architectural blueprint over its lifetime. Unfortunately this is something that is rarely done in real projects. From assessing hundreds of software systems on three continents I know that about 90% of software systems are suffering from severe architectural erosion, i.e. there is not a lot of the original architectural structure left in them, and coupling and dependencies are totally out of control. Read More